ultralyticsを使った物体検出と絞り込み機能
目的
・オープンソースで利用できる物体検出を使い画像の絞り込み機能を作成する
・最終的にローカル環境で『環境構築なし』で動作するものを作成する
想定
・専用のwebページに画像をアップロードすると「変数のみのjsファイル」が返却される
・jsファイルを専用のhtmlで読み込むと絞り込み可能な画像一覧が表示される
ultralyticsの準備
物体検出のライブラリとして「ultralytics(gitのリンク)」を利用します。
こちらは基本的にGPUを搭載したマシンで利用することを念頭に作られていますが、
CPU only のpytorchを導入すればCPUのみで利用が可能です。
本記事では公式で公開されているtorch==1.12.1のCPU版を利用します。
# CPU only pip install torch==1.12.1+cpu torchvision==0.13.1+cpu torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cpu # 続けてultralytics導入 pip install ultralytics
環境構築終わり
物体検出用プログラム
ultralyticsの利用方法が非常に簡便であるため、物体検出するだけであれば3行
from ultralytics import YOLO
model = YOLO('利用するモデルのパス')
model('利用する画像のパス')
利用するモデルはパスではなくモデル名であれば初回利用時に自動的にダウンロードされますが、
使いたいものがあるならgitから先にダウンロードした方が容易です。
モデルの違いについて
ultralyticsの「Detection」用のモデルは2種類公開されています。
それぞれの特徴は
COCO:
・80種のラベルで判定する
・ラベルが少ないため大まかな検出に利用できる
・痒いところに手が届かない場合も多い
・似たものをラベル内で判定しがち(ハリネズミを猫と判定するなど)
Open Image V7
・600種のラベルで判定する
・COCOに比べて詳細に検出される
・ただしconf値(物体検出のconfidence:自信)が低くなりやすい
・人間を「男性,女性,少年,少女,人間(person)」で判定するため「人間の数でまとめる」などができない
このため本記事の作成物ではCOCOで大分類を作り、Open Image V7で小分類を追加しています。
モデルはともに「YOLOv8x」を使っています。
完成物
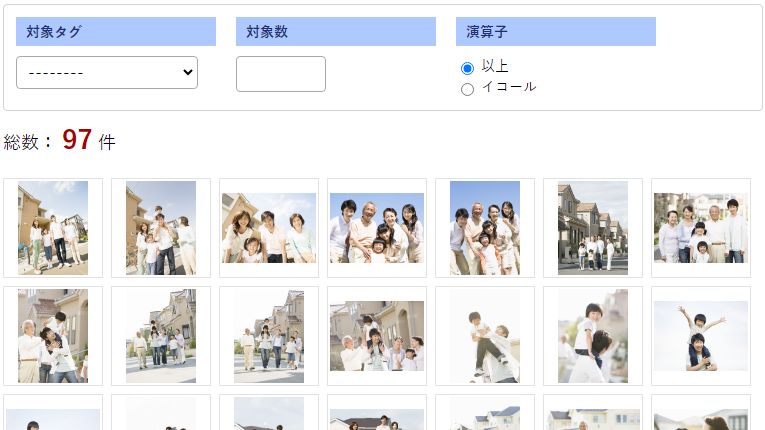
97枚の家族写真をアップロードし
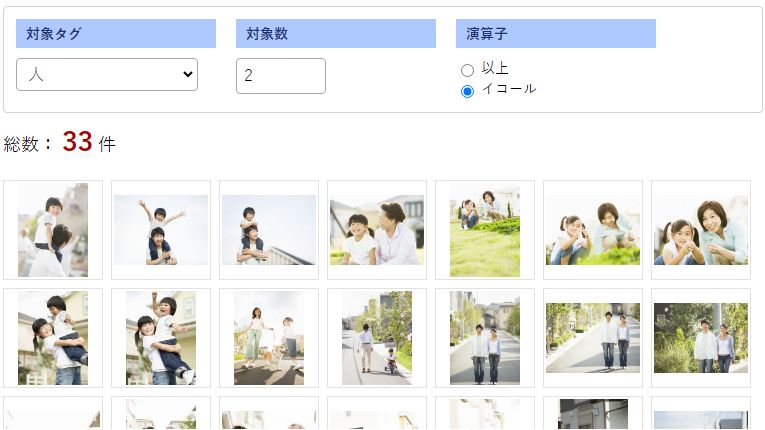
人間が2人だけ写っているものを抽出できるようになりました。
最初に「想定」で記載した通り、最終的にローカルに環境を構築することなく使用できるものを目指しています。
完成物ではultralyticsで検出した内容を
画像に対し「どのラベル」が「何個存在するか」を連想配列(dict)に格納、json化したものを
「let search_data = JSON.parse( ここにjson );」といった内容でjsファイルに保存。
専用のHTMLファイルで読み込めば殆どのブラウザで動作するようにしています。
テストページがあるとわかりやすいのですが、様々な事情により公開予定はありません。
おまけ
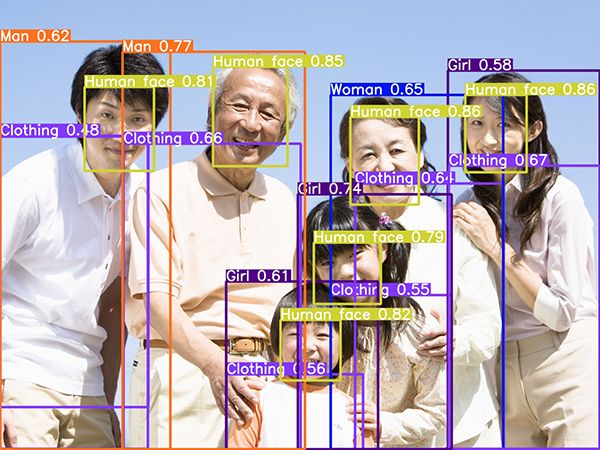
Open Image V7の検出結果を標準搭載の機能でラベリングした場合、
数が多すぎてどこに何があるのかわかりにくい問題がありました。
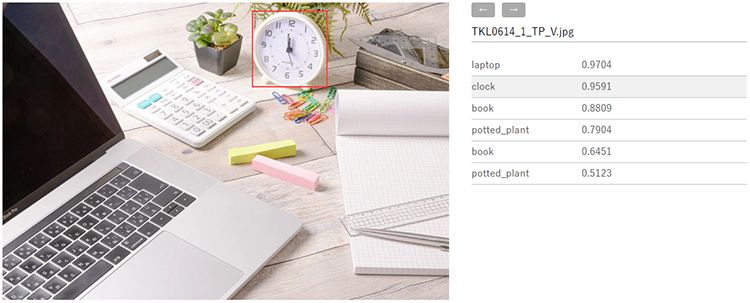
※画像はぱくたそ様の物を利用しています。
そこでマウスを合わせれば座標を確認できるものも作成しました。
大変見やすい。
その際の検出結果の操作メモ
results = model(img_path) cls_list = results[0].boxes.cls.cpu().numpy().astype(int).tolist() conf_list = results[0].boxes.conf.cpu().numpy().astype(float).tolist() xyxy = results[0].boxes.xyxy.cpu().numpy().astype(int).tolist()
検出結果はtensorで返るため、配列に変換してから利用する。
検出結果の末尾に「.cpu().numpy().astype(int).tolist()」をつけると配列になる。
※スコープが生きているので編集するときは注意
cls:ラベルの変数
conf:上記ラベルの一致度
xyxy:検出地点の左上xyと右下xy
これ以外にxywh(検出地点の左上xyに幅と高さ)などがある。
※print(results)ですべて表示できます。