ベクトル検索用のデータセットを作る_コメント収集処理
ベクトル検索用のデータセットを作る_コメント収集処理
お世話になっております。
プログラマーのskkと申します。
最近は
テキストデータのベクトル化とそれに対する検索機能を作りながら
AI検索サービスを色々模索しているような日々です。
ChatGPTは本当に凄いですね…!
ベクトル検索サービスを作るためには
検索対象のデータを用意してそれのベクトルデータを用意して
ベクトル検索用データセットを作る必要があるわけですが、
今回は検索対象のデータを用意する所についての話になります。
ベクトル検索するためには
多くのテキストデータを用意する必要があるということで、
手頃に多くのデータが手に入る所…例えば何かのレビューならどうだろう…
という所からyoutuberのレビューを各所からデータとして拾うことにします。
対象は
youtubeの動画コメントと
掲示板サイト「5ちゃんねる」(以下5ch)での該当youtuberに対するスレッドの書き込み
これら2つから
レビューコメントを取り出してみようと思います。
コメントを取り出したいyoutuberのリストは予め作成したものを用意します。
https://drive.google.com/file/d/1KYYDg6pHtNO0y8GwFtoWNaE34rkXQlFd/view?usp=sharing
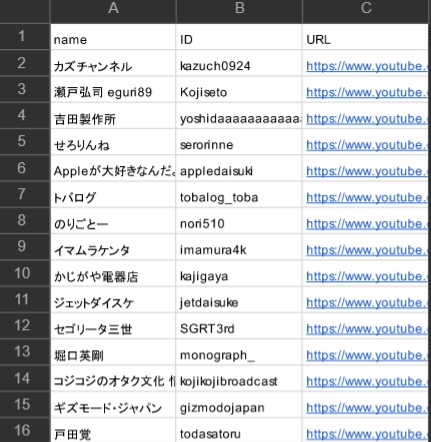
name欄 は 5chからのスクレイピングに、
ID欄 は youtubeからの取得に使用します。
IDはyoutuberごとにチャンネルページの名前の下に表示されている「@」以下の文字を持ってきています。
(カスタムURLとも言われている部分になります。)
① youtubeの動画コメントを取り出してcsv化
youtubeから特定の情報を取り出す場合、
youtube Data APIを使用します。
https://developers.google.com/youtube/v3?hl=ja
▼処理の流れ
csvをloop
ID欄からchannel検索(search.list)
↓
channelID取得したら
channelIDを元に動画一覧取得(search.list)
↓
動画一覧をloop
動画ごとのコメント一覧を取得(commentThreads)
コメントとその時刻を合わせてデータセットとして記録
channelごとにデータセットを一つにまとめて保存
()内は使用するDataAPIのメソッド名になります。
例えば
youtuber一人のコメントを動画2つ×50のコメントの合計100コメントを取得するとした場合には
ID欄からchannel検索(search.list) ↓ channelID取得したら channelIDを元に動画2つ取得(search.list) ↓ 動画1 動画1のコメント一覧を取得(commentThreads) コメントとその時刻を合わせてデータセットとして記録 動画2 動画2のコメント一覧を取得(commentThreads) コメントとその時刻を合わせてデータセットとして記録 2つのデータセットを一つにまとめて保存
という挙動になります。
youtube Data APIを使用する上で、
1日の利用回数上限があり、
https://developers.google.com/youtube/v3/determine_quota_cost?hl=ja
上記の処理であれば一日約47人まで取得できる計算となります。。
以下サンプルプログラムです。
import requests
import pandas as pd
import os
import json
import numpy as np
# Youtube Data API
API_URL = 'https://www.googleapis.com/youtube/v3/'
API_KEY = '[Youtube Data APIのkey(google cloudから取得)]'
data = pd.read_csv('gadget_youtuber.csv')
# コメントと日付をまとめて格納するdataframe
cols = ["comment", "datetime"]
# videoIDからコメント抽出
def print_video_comment(video_id, next_page_token):
# コメントと日付を格納するdataframe
comment_df = pd.DataFrame(index=[], columns=cols)
params = {
'key': API_KEY,
'part': 'snippet',
'videoId': video_id,
'order': 'relevance',
'textFormat': 'plaintext',
'maxResults': 50,
}
#if next_page_token is not None:
# params['pageToken'] = next_page_token
response = requests.get(API_URL + 'commentThreads', params=params)
resource = response.json()
#print(resource)
for comment_info in resource['items']:
# コメント
comment_text = comment_info['snippet']['topLevelComment']['snippet']['textDisplay']
# コメント日時
comment_time = comment_info['snippet']['topLevelComment']['snippet']['updatedAt']
#comment_time = dt_to_str(iso_to_jstdt(comment_time))
comment_series = pd.Series([comment_text, comment_time], index=cols)
comment_df = comment_df.append(comment_series,ignore_index=True,sort=False)
#comment_df = pd.concat([comment_df, comment_series], ignore_index=True)
#if 'nextPageToken' in resource:
# print_video_comment(video_id, resource["nextPageToken"])
return comment_df
# カスタムURLからチャンネルのIDを取り出す
def yt_custom_to_chid(cus_url):
params_custom = {
'key': API_KEY,
'part': 'snippet',
'type': 'channel',
'q': cus_url,
}
response_ch = requests.get(API_URL + 'search', params=params_custom)
resource_ch = response_ch.json()
ret_id = ""
#print(resource_ch["items"][0]["id"]["channelId"])
return resource_ch["items"][0]["id"]["channelId"]
# チャンネルIDから最新動画ID一覧取得
def yt_chid_to_videoid_list(channel_id):
param_channel = {
'key': API_KEY,
'part': 'snippet',
'type': 'video',
'channelId': channel_id,
'order': 'videoCount',
'maxResults': 2,
}
response_mov = requests.get(API_URL + 'search', params=param_channel)
resource_mov = response_mov.json()
video_id_list = []
if "items" in resource_mov:
for video_info in resource_mov['items']:
video_id = video_info["id"]["videoId"]
video_id_list.append(video_id)
list(video_id_list)
return video_id_list
for row in data.itertuples():
print(row.name)
print(row.ID)
print(row.URL)
comment_sum_df = pd.DataFrame(index=[], columns=cols)
streamer_id = row.ID
streamer_name = row.name
dataset_name = row.ID + "_youtube_comment"
# URL->channelID
ch_id = yt_custom_to_chid(row.ID)
# channelID->videoid_list
vid_list = yt_chid_to_videoid_list(ch_id)
for vid in vid_list:
df_one = print_video_comment(vid, None)
comment_sum_df = pd.concat([comment_sum_df, df_one], ignore_index=True)
#comment_sum_df.append(df_one, ignore_index=True)
print(comment_sum_df.shape)
# CSV ファイル ([ユーザーID]_youtube_comment.csv) として出力
comment_sum_df.to_csv(dataset_name+".csv")
print("finish youtube crawl!")
② 5ちゃんねるの書き込みをスクレイピングしてcsv化
5chの書き込みを持ってくるためには
HTML情報に対するスクレイピングが必要となります。
ここで
5chの公式スレッド検索機能を使います。
https://find.5ch.net/search?q=
ここにyoutuberの名前を入れて検索して
一番目に見つかったスレッドの中身を取得することにします。
▼処理の流れ
csvをloop
name欄の内容からスレッド検索
↓
スレッド検索結果から
一番目のスレッドのHTMLを取得
↓
HTMLで取得した書き込みの中から最新100件の書き込みをloop
書き込みとその時刻を合わせてデータセットとして記録
channelごとにデータセットを一つにまとめて保存
HTMLを取得するためには
pythonモジュールのbeautifulSoup4(bs4)というモジュールを使用しています。
指定したURLの内容を構造体で取り出すことができる便利なモジュールとなっております。
以下サンプルプログラムです。
# ライブラリのインポート
import requests, bs4
import re
import time
import pandas as pd
import urllib
import urllib.request
import sys
#絵文字処理
import emoji
import pandas as pd
import os
import json
import numpy as np
# コメントと日付をまとめて格納するdataframe の列名
cols = ["comment", "datetime"]
# 下準備
log_database = [] # スレッドの情報を格納するリスト
search_base_url = "https://find.5ch.net/search?q=" # スレッド検索ページ
# 読み込む配信者リスト
data = pd.read_csv('gadget_youtuber.csv')
for row in data.itertuples():
streamer_id = row.ID
streamer_name = row.name
dataset_name = row.ID + "_5ch_comment"
search_word=row.name
search_url = search_base_url+search_word
# スレッド検索スクレイピング処理
th_search = requests.get(search_url)
th_search_soup = bs4.BeautifulSoup(th_search.text, "html.parser")
# ページが見つからなかった時の処理
if th_search_soup.find(class_="search_not_found"):
print("not found")
#sys.exit()
continue
# スレッド一覧が格納されたaタグ一覧の取得
thread_table = th_search_soup.find(class_="container-search")
thread_row = thread_table.find("a",class_="list_line_link")
thread_row_title = thread_table.find("div",class_="list_line_link_title")
# 最初の1行
if thread_row == None:
# スレッドが検索に出てこなかったら次
print("thread not found")
#sys.exit()
continue
thread_url = thread_row.get('href')
# 1スレッド内容スクレイピング処理
th_res = requests.get(thread_url)
th_res_soup = bs4.BeautifulSoup(th_res.text, "html.parser")
thread_responses = th_res_soup.find_all(class_="post")
# データセット登録用dataframe用意
res_sum_df = pd.DataFrame(index=[], columns=cols)
# 逆順にレスをループ 最新100件を取る
for i,thread_response in enumerate(list(reversed(thread_responses))):
if i >= 100:
break
thread_res_date = thread_response.find("span",class_="date")
thread_res_text = thread_response.find("div",class_="message")
thread_res_date = re.sub(re.compile('<.*?>'), '', str(thread_res_date))
thread_res_date = re.sub(re.compile('\(.*?\)'), '', str(thread_res_date))
thread_res_date = re.sub(re.compile('\.\d*'), '', str(thread_res_date))
thread_res_text = re.sub(re.compile('<.*?>'), '', str(thread_res_text))
thread_res_text = emoji.replace_emoji(thread_res_text)
#print(thread_res_date)
#print(thread_res_text)
res_series = pd.Series([thread_res_text, thread_res_date], index=cols)
res_sum_df = res_sum_df.append(res_series,ignore_index=True,sort=False)
# CSV ファイル ([ユーザーID]_5ch_comment.csv) として出力
res_sum_df.to_csv(dataset_name+".csv")
print("finish 5ch crawl!")
終わりに
上記の方法でyoutube、5chそれぞれからレビューコメントを取り出すことが出来ます。
次回に取得したcsvをベクトル検索データとして加工する処理を説明したいと思います。
最後に注意点として
今回レビューコメント抜き出し対象のyoutube、5chも含め、
あらゆるサービスからの内容を抜き出す場合には、
用途、あるいは抜き出し自体に禁止事項がある場合があります。
必ず各サービスのコンテンツ利用に関しての注意をお守りいただきますようお願い致します。